

🌐 Some surprising facts about ImageNet and geospatial models
PLUS: predicting wildfires using deep learning, estimating emissions from road intersections and more.


Hey guys, here’s this week’s edition of the Spatial Edge. We’re a weekly round-up of geospatial news that’s more topical than a Kendrick halftime show. The aim is to make you a better geospatial data scientist in less than 5 minutes a week.
In today’s newsletter:
Geospatial models & ImageNet: Should models train on domain-specific datasets?
Wildfire Predictions: Transformer models improve next-day fire forecasts.
Urban Emissions: CO₂ and pollution forecasting at road intersections.
Industrial Land Use: High-resolution mapping of global industrial zones.
Climate Forecasting: APEC dataset offers seasonal climate predictions.
First up, I’m going to be working on some projects measuring air pollution and emissions from vehicles (using big data and remote sensing data).
If you’ve got experience in this field I want to hear from you.
You can hit me up by replying to this email.
Research you should know about
1. Should we be training deep networks on more domain-specific datasets?
If you’ve got any experience with training computer vision deep learning models, then you’ve certainly come across ImageNet. In short, it’s a collection of over 14 million images that are carefully annotated and organised into over 20,000 categories.
It wouldn’t be an exaggeration to say this dataset has facilitated the development of several major computer vision models.
However, despite its central role in the computer vision space, there are always attempts to improve upon it. Some reasons are:
Bias: e.g. it reflects the biases of its data sources (e.g., Flickr, Google Images) and annotators
Domain gap: its focus on everyday objects (cats, cars, chairs) may not align perfectly with remote sensing needs, like identifying deforestation.
Annotation issues: Errors, ambiguous labels, and outdated categories (e.g., technology from the 2000s) affect the dataset
Particularly in the remote sensing space, there have been many attempts (e.g. see this and this) to create more domain-specific datasets to train deep learning models on.
Well, the newest addition to this literature is this paper by some folks from the University of Missouri, Duke and Stanford. They examine whether pre-training deep networks on satellite imagery can outperform pre-training on ImageNet for tasks like identifying crops or floods.
The hypothesis is pretty simple: training models on satellite images (Sentinel-2) should be more effective than using ImageNet, which consists of everyday objects like cats and cars. To test this, they created GeoNet, a dataset of one million Sentinel-2 images, and compared models trained on it against those trained on ImageNet.
The results?
They tested the models on six downstream tasks related to segmentation and classification. Surprisingly, there was little difference between training a model on GeoNet and ImageNet. GeoNet had only a slight advantage, and ImageNet remained pretty competitive. Given the high computational cost of training on domain-specific datasets, the study suggests that sticking with ImageNet pre-training might still be the more practical choice for many remote sensing applications.
At the end of the day, this leads us to keep coming back to ImageNet. While it has its problems, it’s still (1) reliable, and (2) easy to implement.
2. Improving wildfire predictions with deep learning

A recent study by a team from the University of Montana and Missouri explores the potential of using transformer-based deep learning models for predicting next-day wildfire spread.
They tested the SwinUnet model against other state-of-the-art methods on the WildfireSpreadTS dataset, a large benchmark dataset of historical wildfire events.
Two scenarios were tested:
models trained with only the previous day's data and
those trained with five days of historical data.
The results showed that SwinUnet achieved the highest prediction accuracy among all models tested. Models trained on multi-day input consistently outperformed single-day models. This is no surprise and just reinforces the importance of using time-series data for fire forecasting.
On topic, they found that pre-training on ImageNet significantly improved the model’s accuracy, increasing its average test precision from 0.351 to 0.383 for single-day inputs and from 0.365 to 0.404 for multi-day inputs.
However, one thing to be aware of is the model struggles with detecting sudden fire starts (i.e. ‘ignition events’). This suggests it may struggle to capture fine-scale changes, which could make it less reliable for predicting early-stage wildfires.
3. CO₂ and energy forecasting at urban intersections
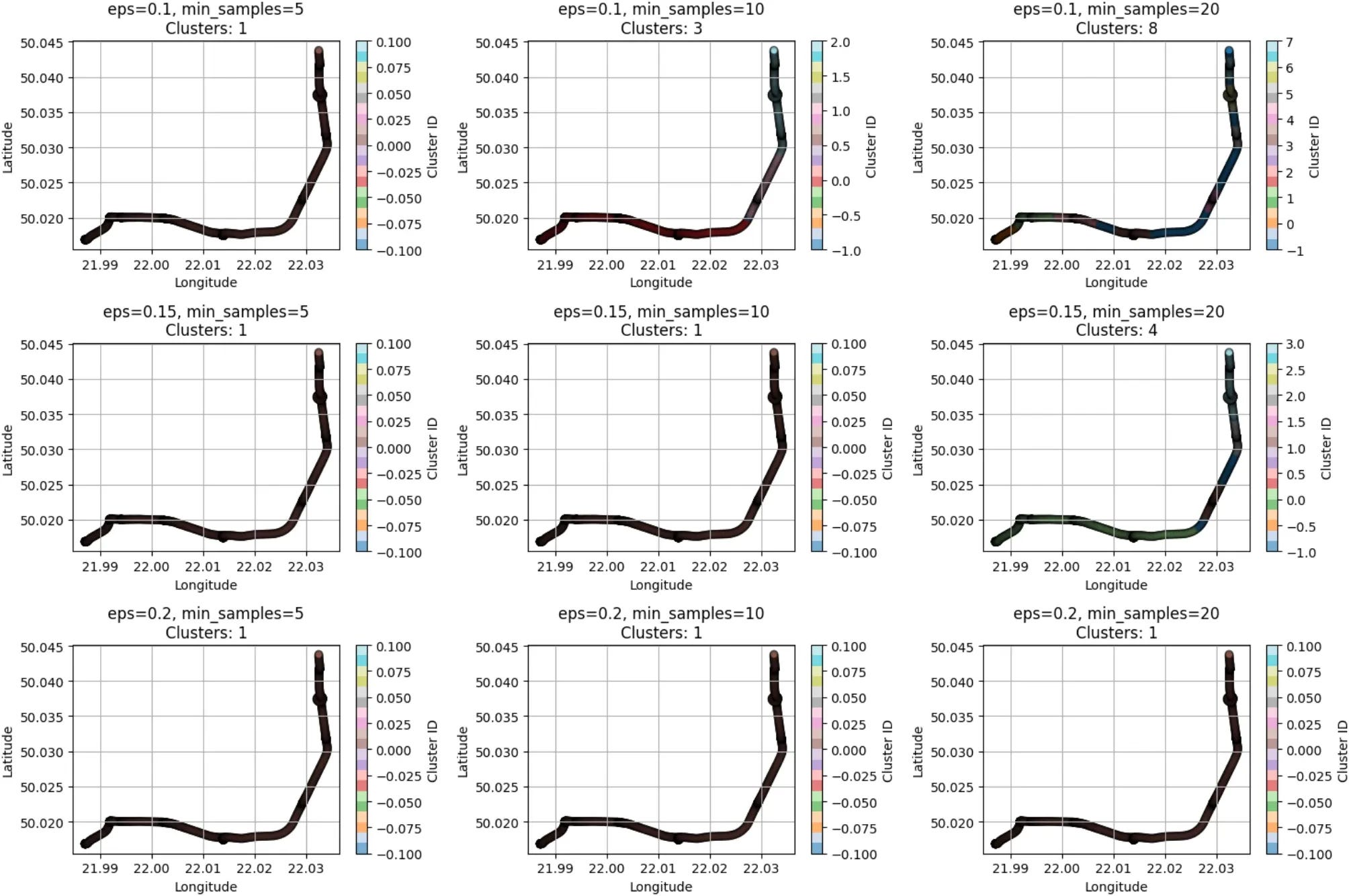
A new study published in Scientific Reports looks at ways to predict CO₂ emissions and energy use for vehicles in busy intersections.
They wanted to examine whether the ‘stop-and-go’ behaviour of vehicles at intersections increases pollution (since it may create extra exhaust releases). To examine emissions, the author collected real-world driving data with portable measurement systems and then organised the records using a clustering algorithm known as DBSCAN to isolate intersection-specific segments.
They tested a bunch of different models and found XGBoost the best in forecasting CO₂ output and power draw. They validated results using intersection experiments in Rzeszów, Poland, and the approach often performed better than the COPERT reference method. The final method was applied in simulation scenarios, using Vissim, to optimise road layouts and signal timings.
But before you get too excited, the study has major limitations. The data comes from just one 16-km route in Rzeszów, Poland (a city that doesn’t represent traffic conditions in places like Mumbai or Los Angeles). The sample size is also pretty small, with only twelve passenger cars, leaving out heavy trucks and other key contributors to urban emissions.
So the bottom line is this is an interesting study, but not super generalisable.
Geospatial Datasets
1. Industrial land use dataset
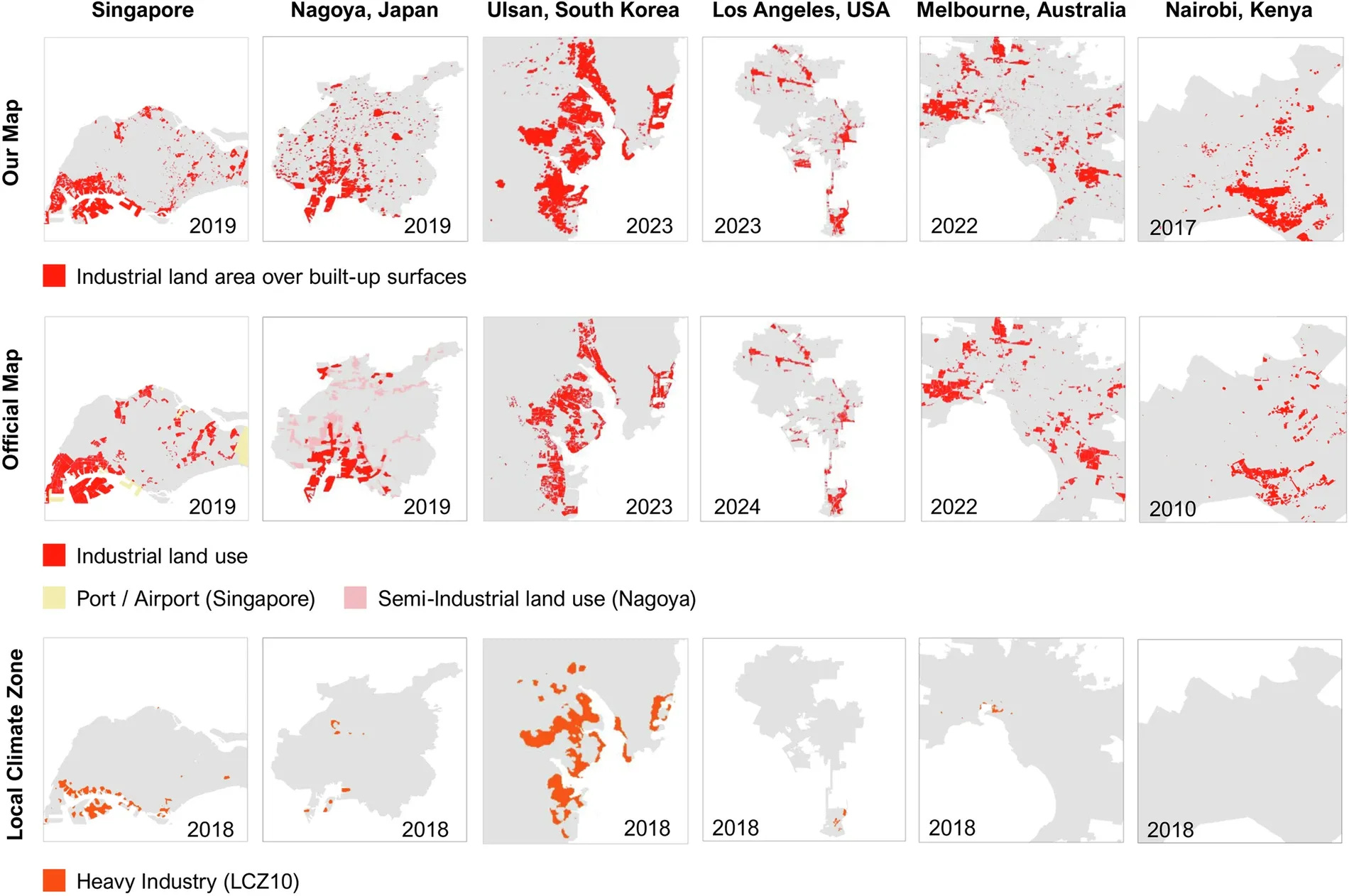
This 10-m Industrial Lands dataset maps industrial land use across 1,093 large global cities from 2017 to 2023. It can help track industrial expansion, CO2 emissions, and environmental impacts. You can access the data here and the code here.
2. Multi-modal vision language dataset
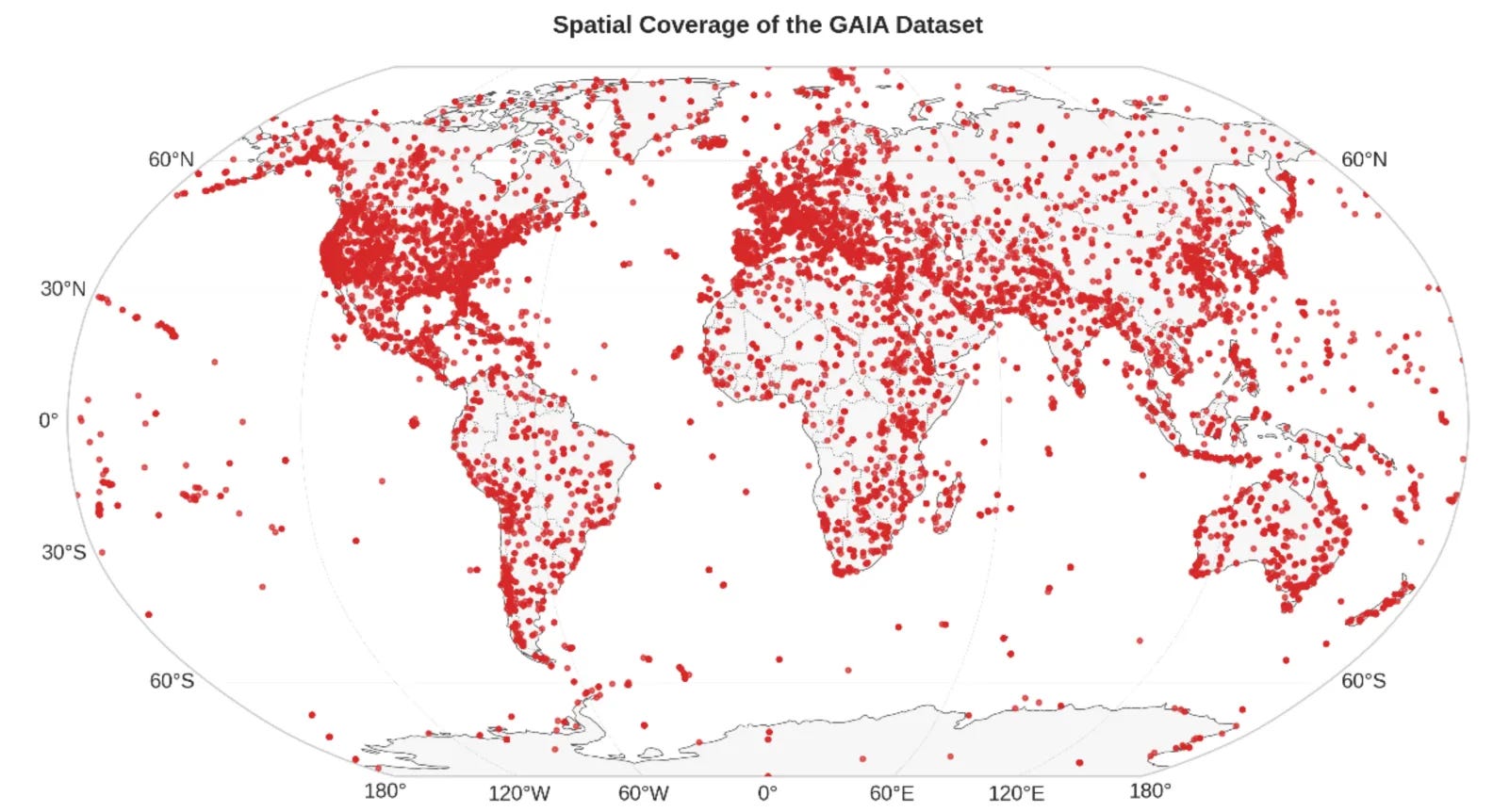
The GAIA dataset is a multi-modal vision-language dataset that features 205,150 image-text pairs spanning 25 years of Earth observation data, with descriptions generated using GPT-4o. GAIA improves classification, retrieval, and interpretation of satellite images, supporting applications in urban planning, environmental monitoring, and disaster response.
3. Multi-Model Ensemble Datasets

The APEC Climate Center Multi-Model Ensemble (MME) dataset offers seasonal climate predictions for key variables like temperature, precipitation, and sea surface temperature. It covers the globe from 1991 to 2022. You can access the data here and the code here.
Other useful bits

WorldPop is developing high-resolution maps to predict how climate change will reshape global populations by 2100. Backed by a £5.6M grant from the Wellcome Trust, the FuturePop project will estimate future population sizes, ages, and distributions to help governments and organisations plan for climate-related risks. This data will support disaster response, health planning, and resource allocation in a rapidly changing world.
GeoAnalyze is a new Python package that simplifies and speeds up geospatial processing without the need for paid GIS software. It offers fast, scalable watershed delineation, generating key outputs like basin area, flow direction, and subbasins in under 30 seconds for large datasets.
NASA’s Lunar Trailblazer satellite has launched aboard a SpaceX Falcon 9 to map and locate water on the Moon, particularly in its permanently shadowed polar craters. This mission will help examine how lunar water could be used for astronaut survival, rocket fuel, and long-term Moon bases. Scientists also hope it will shed light on the origins of water on both the Moon and Earth.
Jobs
Mapbox is looking for a Machine Learning Engineer under their Search Data team. The job is remote.
World Bank is looking for a Lead Specialist to spearhead the technical work on digital transformation initiatives in Washington DC.
The United Nations Environment Program is looking for a front-end developer with geospatial skills in Paris.
The Allen Institute is looking for a Lead Machine Learning Engineer in Earth Systems in Seattle, WA.
Just for fun

After President Trump renamed the Gulf of Mexico as the "Gulf of America", mapping services like Google Maps now display different names based on location—U.S. users see "Gulf of America," Mexico sees "Gulf of Mexico," and others see both. This is what I see from Manila:
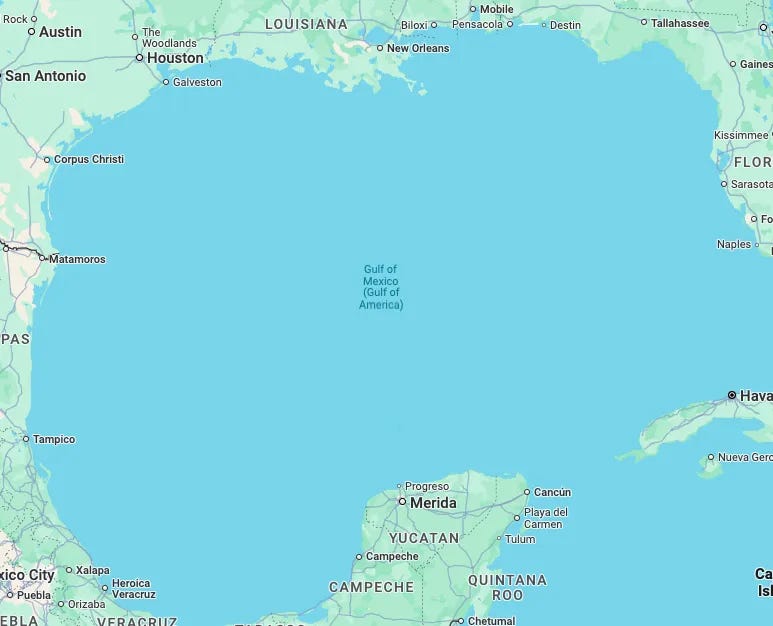
That’s it for this week.
I’m always keen to hear from you, so please let me know if you have:
new geospatial datasets
newly published papers
geospatial job opportunities
and I’ll do my best to showcase them here.
Yohan