

What the heck is a foundation model?
Foundation models explained in simple terms

Foundation models are the sexy new topic in the data science and geospatial worlds.
It’s a term we’ll hear more of in the coming months and years.
If you’re new to this term, then one example of a foundation model is IBM and NASA’s Prithvi.

Prithvi is an open-source model that has a bunch of different use cases. It can be used to:
track changes in land use (e.g. if an agricultural area became urbanised)
monitor natural disasters (e.g. the impact of flooding)
predict crop yields (i.e. how much crops farmers can harvest)
cloud removal (i.e. remove clouds from satellite images)
This model is much easier and cheaper to use than if you had to build a model from scratch for each of these four use cases.
But the main question many of us have is “what the heck is a foundation model”?
In this post, I attempt to explain foundation models in simple terms. I initially thought this would be straightforward. And the intuition behind these models is straightforward. But the problem with explaining these things is that it requires us to know certain concepts — e.g. context windows, tokens, parameters, etc.
So my plan here is to breakdown everything and provide you with the 101 on foundation models.
So what the heck is a foundation model?
In a nutshell a foundation model provides general capabilities. In other words, it can perform a bunch of different tasks.
Before, if you wanted to use satellite data to detect flooding, you’d have to train a specific model to do so. If you wanted to use satellite data to assess which areas in a country are classified as forest, you’d have to train a separate model.
With foundation models like Prithvi, you just need the one model for a bunch of different use-cases.
There are actually a few characteristics of a foundation model:
General—they can perform a range of different tasks
Pre-trained—these models are already trained on data
Large scale—they’re usually trained on a lot of data
Adaptable—they can be fine-tuned for more specific tasks
Let’s take a look at each of these:
1. Generalisable
This is pretty much what I described above in relation to Prithvi. Prithvi can do a number of different things related to processing and analysing satellite data.
The most well-known foundation model, GPT-4, can similarly do several different tasks:
summarise text
generate computer code
translate between languages, etc.
So hopefully this idea of ‘generalisability’ makes sense by now.
2. Pre-trained
Foundation models are all pre-trained on data. This means these models can be used off-the-shelf.
This is a bit different to how we previously built AI models.
For example, in the past, if I wanted to detect cropland in a satellite image, I’d need some training data.[1]

The simplified process would look like the following:
We’d need to get a lot of satellite images where humans had labelled whether a pixel was cropland or not (i.e. “labelled data”).
We’d feed some of that data into a model so that it could learn whether a pixel was cropland or not.
We’d then show it some of the labelled data from step 1, which wasn’t used in step 2. We’d ask it to estimate which pixels were cropland.
We’d then compare the results from step 3 to the ground-truth labelled data to assess its accuracy.
We’d then tweak elements of the model from step 2 to try and improve the accuracy.
Now in this simplified example, you get a sense of the complexities involved in creating a model developed specifically for classifying cropland. You need to:
acquire training data
build a model
test the model
tweak the model to get more accurate results
PLUS this model is only able to identify cropland. It can’t be used for other things like detecting forest fires.
A foundation model like Prithvi on the other hand, can be used off the shelf. It has already been trained on satellite data from Lantsat 8 and Sentinel-2.
So with Prithvi, we don’t really need to worry about all the steps I discussed above [2].
This makes it much easier and quicker to use these types of foundation models.
3. Large Scale
Now it’d be a problem if a model like Prithvi was trained on a couple of satellite images. That would lead to it being wildly inaccurate and unable to perform a range of different tasks.
Instead, most foundation models are trained on A LOT of data.
GPT-4 was trained on approximately 13 trillion tokens, and has about 1.7 trillion parameters.
In short, these models have been trained on massive amounts of data.
Now you might be wondering, what the heck are tokens and parameters?
I’ve got you.
3.1 What’s a token?
A token is essentially a chunk of data.
Let’s look at a sentence like “satellite data is helpful”. This sentence is typically broken up into separate chunks (i.e. tokens). So a simple approach would be to break this up into five separate tokens of “satellite”, “data”, “is”, “help”, “ful”.
Notice that “helpful” has actually been split up into two separate chunks of “help” and “ful”. The bottom line is that for language models a word doesn’t always equal a token.

3.2 What’s a parameter?
You’ll often hear foundation models talking about how many parameters it has.
E.g.
Bard has 137 billion parameters
Claude 2 has over 130 billion parameters
LLaMA has 65 billion parameters
GPT-4 has 1.7 trillion parameters
But what exactly does this mean?
Taking a step back, we need to understand that each of these foundation models use some kind of AI model (hopefully you've got that so far). In most cases these are neural networks.
Foundation models take training data (in the case of Prithvi it's a lot of satellite data), it interprets this data, and learns about the data.
Each parameter encodes the “knowledge" it learns from the data—e.g. relationships between words, context, and so on. In other words, you can think of parameters as representing the learned knowledge of the model. In simple terms, the more the parameters, the more it has learned.
There are two main types of parameters: weights and biases.
To understand these (in simple terms), let's look at an example.
If we feed a new satellite image into Prithvi, it’ll essentially break that image up into many different slices of information. 'Weights' control which information is given more attention (weighted more) by the model. While 'biases' select the baseline or starting point from which it begins processing data.
So these parameters guide the network in processing new information and making decisions based on what it has learned before.
Now the last point to make here is that more parameters does not equal a better model. Having more parameters increases accuracy up to a point.
Initially, adding more parameters can improve a model's ability to learn from data and make better predictions. More parameters means the model can capture nuances in the data. But beyond a certain point, more parameters can cause the model to overfit.
And yes — I’m pretty much describing the concept of diminishing marginal utility.
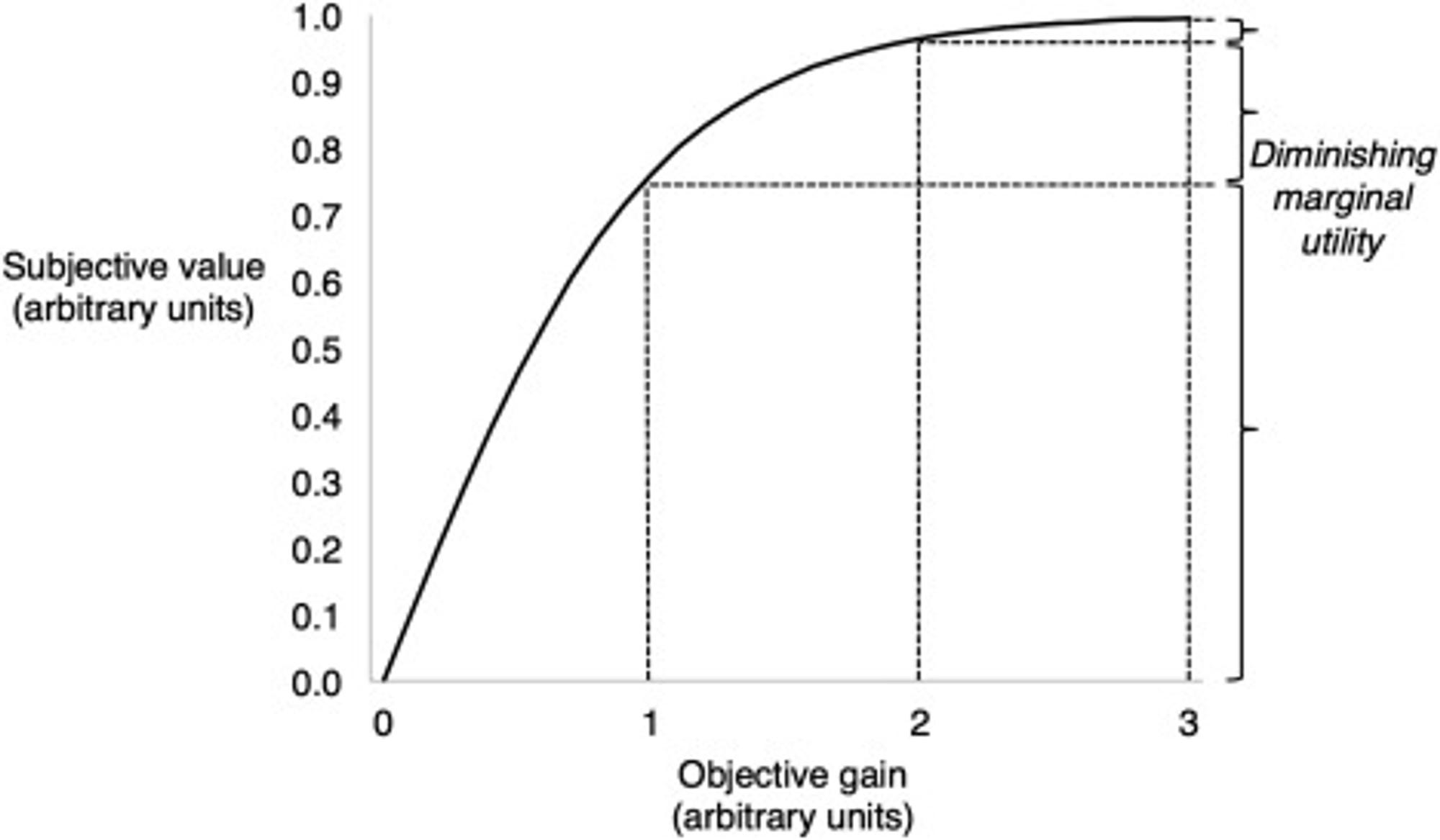
Overfitting means that the model learns about the training data too well, so it thinks the training data's noise and random fluctuations are meaningful. This means the model performs badly on new data because it's tailored too much to the specifics of the training data.
3.3 context windows
The last concept related to "large scale" I want to cover are 'context windows'. Context windows are essentially a model's short-term memory. It's the amount of recent information (e.g. words in the case of GPT-4) the model can look at and remember while it's working on something.
For example, imagine for a minute that ChatGPT’s context window is 100 tokens. If you have a conversation with ChatGPT, it will only recall the last 100 tokens you’ve given it. All other tokens will be outside of its context window.
Hence any important information that was given to it earlier on will essentially be forgotten.
By the way, in reality GPT-4’s context window is about 32k tokens:

4. Adaptability
The last characteristic of a foundation model is its adaptability.
Adaptability means they can be ‘fine-tuned’ for specific tasks or domains with relatively small additional datasets. This adaptability is what makes them 'foundational' – a base model that can be adapted or built upon for various specific applications.
Let’s break this down by looking at an example of how we can adapt GPT-4 for medical applications:
Initial Training: GPT-4 is trained on lots of different text. For example, books, academic articles, websites, internet forums, etc. It learns general language patterns, facts, and different writing styles.
Domain-Specific Data: To adapt GPT-4 for medical applications, it's further trained (fine-tuned) on text specific to these fields. This could be medical journals, transcripts of lectures, and medical textbooks, which GPT-4 hadn’t seen previously.
Specialised Knowledge: Through this process, GPT-4 learns medicine-specific concepts, specialised vocabulary, and the ability to generate text that aligns with the medical profession.
OpenAI even has a ‘cookbook’, which shows how to fine-tune its models:

Now fine-tuned models are not the same as domain-specific GPTs.
4.1 Fine-tuned vs domain-specific GPTs
To better understand this, let’s look at the example of BloombergGPT.
This was a big marketing coup for Bloomberg, who launched a large language model at the beginning of the ChatGPT craze. It was built using Bloomberg’s proprietary financial data:

It’s a 50 billion parameter model (you know what this means now), and it was heralded as the best large language model for financial analysis.
This prompted many talking heads in the AI space to predict that each industry would need to build their own domain-specific GPTs. The prediction was that ChatGPT’s market share would get depleted by all of the domain-specific GPTs that would surely proliferate.
4.2 How good are domain-specific GPTs?
However, in a recently released paper by Li et al. (2023), they compare GPT-4’s performance to BloombergGPT:

They found that for the following finance-specific tasks, GPT-4 performed better than BloombergGPT:
Sentiment Analysis (e.g. figuring out if a piece of writing has a positive, negative, or neutral tone)
Question Answering (QA) (i.e. the ability to understand and answer questions)
Headline classification (i.e. it could better estimate if a news headline corresponded to an asset price going up or down)
However, for Named Entity Recognition (NER) (e.g. identifying specific names/terms in text, like people, places, companies, etc.), BloombergGPT performed better.
The point here is that, amongst all the AI hype, it’s important to realise that simply having a domain-specific GPT doesn’t automatically mean it’s better at performing domain-specific tasks than some of the more general models (like GPT-4).
Conclusion
So there you have it — an overview of foundation models. We’re going to be seeing A LOT of foundation models emerging in the coming months and years. So having some baseline understanding of what they’re about will be helpful.
My prediction is that foundation models are going to significantly lower the barriers for people to start getting involved in geospatial analysis. But at the same time, there’s going to be a profusion of bad-quality foundation models.
In any case, I wanted this article to set the scene for future examinations of geospatial foundation models. Now that we have a baseline knowledge, we can build on top of it by looking at more of the specifics. So stay tuned for those by hitting subscribe.
Endnotes
[1] In this example I’m talking about supervised learning to keep things simple.
[2] Of course, models like Prithvi can be fine-tuned by its users, but it is designed to be useable out of the box.